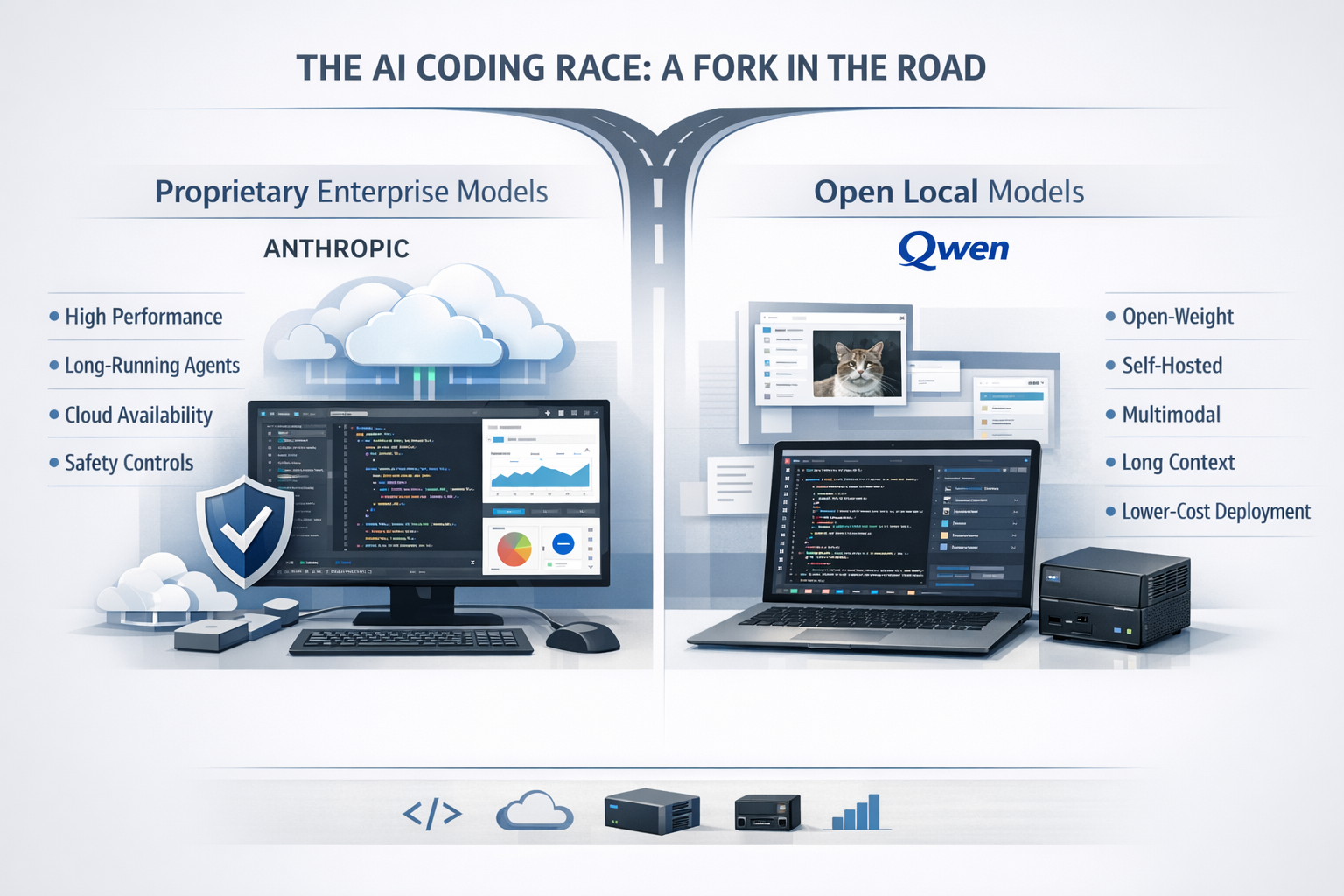
The race for AI coders is splitting in two
The contest to build the most useful artificial-intelligence model for software work is no longer a single race. It is becoming two.
On one side are companies like Anthropic, pushing expensive, tightly controlled systems aimed at enterprises that want top-tier coding performance, long-running agents and broad cloud availability. On the other are model makers like Alibaba’s Qwen team, betting that developers will increasingly value something else: strong coding and multimodal performance in a model they can run, inspect and adapt themselves.
That divide came into sharper focus this week as Anthropic introduced Claude Opus 4.7, its newest flagship model, and Qwen released Qwen3.6-35B-A3B, an open-weight vision-language model explicitly pitched for coding agents and local deployment.
Both releases target one of the most commercially important corners of the generative-A.I. market: tools that can write, debug and reason across large code bases. And both arrive at a moment when developers are looking beyond chatbot fluency toward systems that can reliably carry out extended technical work.
Anthropic pushes performance — with limits
Anthropic said Claude Opus 4.7 is a direct upgrade over Opus 4.6, with particular gains in coding and “long-running agent” tasks. The company said the model improved task resolution by 13 percent on its internal 93-task coding benchmark, while also strengthening image handling, instruction following and tool use. It added a new “xhigh” reasoning-effort setting, giving users more control over how much computation the model devotes to a problem.
The company kept pricing in line with Opus 4.6, a notable decision in a market where frontier-model improvements are often accompanied by higher usage costs. Anthropic has also made the model broadly available across its own Claude products and API, as well as through Amazon Bedrock, Google Cloud Vertex AI and Microsoft Foundry — a signal that it sees Opus 4.7 as infrastructure for corporate software teams, not merely as a showcase model.
But Anthropic paired the launch with an unusual message about restraint. The company said it had deliberately made Opus 4.7 less capable in certain cybersecurity areas than Mythos Preview, another Anthropic system, and combined the release with tighter cyber-abuse safeguards and a Cyber Verification Program for legitimate security users.
That decision reflects a growing tension in advanced model development. The same abilities that make A.I. systems more useful for debugging, systems administration and defensive security research can also make them more useful for malicious intrusion or exploit development. Anthropic’s choice suggests that some frontier labs are increasingly willing to trade away a degree of raw capability in sensitive domains to reduce misuse risk.
Whether that balance satisfies customers remains unclear. Security teams often want exactly the kinds of deep technical reasoning that companies are now trying to constrain. Anthropic is effectively arguing that it can preserve strong coding performance for mainstream use while narrowing more dangerous cyber capabilities at the edges.
Qwen bets on openness and local use
Alibaba’s Qwen team made a very different pitch.
Its new Qwen3.6-35B-A3B model is being released under an Apache 2.0 license, making it a far more permissive offering than proprietary rivals. The model uses a sparse mixture-of-experts architecture with 35 billion total parameters but only 3 billion active at a time, an approach meant to deliver stronger performance than a dense model of similar inference cost.
Qwen has described the model as the first open-weight variant in the Qwen3.6 family, built for agentic coding and multimodal tasks. It includes a native vision encoder and a long context window of 262,000 tokens, which the company says can be extended to roughly 1.01 million. In practice, those specifications are aimed at an increasingly important use case: analyzing large repositories, documentation and screenshots together, while remaining practical to serve on common stacks or, in some cases, to run locally.
The model card leans heavily into that promise. Qwen says the system is designed for frontend work, repository-level reasoning and self-hosted deployment. In a market increasingly crowded with polished cloud-based coding assistants, that is a direct appeal to developers who want control over latency, privacy, customization and cost.
That appeal is not theoretical. Within hours of the release, developers were already running quantized versions of the model on laptops and testing it against proprietary systems. In one widely shared informal comparison, the model produced cleaner SVG illustrations than Claude Opus 4.7 on whimsical image-generation prompts — hardly a definitive benchmark, but a vivid demonstration of how quickly open models can spread into hands-on developer experimentation.
Coding has become the battleground
The focus on coding is not accidental. Writing software has emerged as one of the clearest areas where large language models can generate immediate economic value. Unlike open-ended conversation, coding offers abundant training data, structured feedback and measurable outcomes. It is also closely tied to lucrative enterprise spending.
That helps explain why model makers are now emphasizing not just benchmark scores, but longer-horizon workflows: managing tools, navigating repositories, interpreting screenshots, following instructions over many steps and sustaining performance over large contexts. The ambition is no longer simply to autocomplete functions. It is to build systems that can behave more like junior collaborators — or, at least, increasingly competent ones.
Anthropic’s strategy is to dominate the high end of that market with a proprietary model distributed across major cloud platforms and wrapped in safety controls. Qwen’s strategy is to offer a compelling alternative for developers and organizations that do not want to depend entirely on a closed vendor.
Those are not mutually exclusive markets, but they are different ones. A large company building internal coding agents may prefer the polish, support and managed integrations of a closed model. A startup, research group or independent developer may prefer an open-weight system that can be tuned, self-hosted and embedded without the same constraints.
The real test is still ahead
For all the confident claims, the central question remains unresolved: how well do these models perform in messy, real-world software work?
Anthropic’s strongest numbers rely largely on internal or partner evaluations. Qwen’s release is supported by benchmark tables comparing the model with systems including Claude Sonnet 4.5 and Gemma 4 across coding, reasoning and vision-language tasks. But benchmark gains do not always translate cleanly into daily use, especially in environments where tasks are ambiguous, repositories are inconsistent and errors can compound over many steps.
That uncertainty is especially important now because buyers are becoming more discerning. In the past, a new model could make headlines by scoring higher on a familiar leaderboard. Today, developers want to know whether a model can survive a week of bug triage, interface redesigns, dependency breakage and undocumented edge cases.
The split emerging in this week’s releases — frontier proprietary power versus open, efficient deployability — may prove more consequential than any single benchmark result. It suggests that the coding-assistant market is maturing into a broader ecosystem, with different winners depending on what users value most: maximum capability, tighter safety controls, local control, lower cost or the freedom to build without permission.
For now, Anthropic and Qwen are advancing different answers to the same question. As A.I. coding tools move from novelty to infrastructure, that question is becoming harder to avoid: not just which model is smartest, but which one developers will actually want to work with.
Sources
Further reading and reporting used to add context:
- Introducing Claude Opus 4.7 \ Anthropic
- https://agent-wars.com/news/2026-04-16-qwen3-6-35b-a3b-on-my-laptop-drew-me-a-better-pelican-than-claude-opus-4-7
- https://www.anthropic.com/news/claude-4/
- https://red.anthropic.com/2026/firefox/
- https://aiforautomation.io/news/2026-04-03-claude-hit-reliability-threshold-burnout-coding
- https://huggingface.co/baa-ai/Qwen3.5-35B-A3B-MINT-28GB-GGUF
- https://www.lines.com/prediction-markets/tech/claude-4pt7-released-on
- https://www.anthropic.com/research/economic-index-march-2026-report/
- https://www.anthropic.com/transparency
- https://www.anthropic.com/research/deprecation-updates-opus-3
- https://support.anthropic.com/en/articles/8114494-how-up-to-date-is-claude-s-training-data
- https://red.anthropic.com/2025/smart-contracts/2025/project-vend-2/2025/project-vend/2026/property-based-testing/2026/zero-days/cyber-toolkits/index.html
- https://openreview.net/pdf/dee99645ee7b7c713c6cbc1c723d3ed9facaa206.pdf
- https://cdnc.heyzine.com/files/uploaded/1e1656196e738fee304e128c3ac24e1940dfd943.pdf
- https://openreview.net/pdf?id=lSM6MtjQcM
- https://www-cdn.anthropic.com/c788cbc0a3da9135112f97cdf6dcd06f2c16cee2.pdf
- https://aclanthology.org/2025.ijcnlp-long.17.pdf
- https://openreview.net/pdf/0bab4c86189a34c853ef9ed30380929e8a6298ba.pdf
- https://huggingface.co/spaces/benxa34/Qwen-Qwen3.5-35B-A3B
- https://qwen.ai/blog?id=qwen2.5-llm
- https://qwen.ai/blog?id=qwen2
- https://huggingface.co/titan0115/Qwen3.5-35B-A3B
- https://huggingface.co/Qwen/Qwen3.5-35B-A3B
- https://huggingface.co/txn545/Qwen3.5-35B-A3B-NVFP4
- https://qwen.ai/blog?id=qwen1.5
- https://qwen.ai/cookies-notice
- https://qwen.ai/blog?from=research.res&id=6aed6aa257238a0b6c77a6753f180350c2fecc4a
- https://huggingface.co/collections/baa-ai/qwen35-35b-a3b
- https://gist.github.com/kibotu
- https://qwen.ai/research/
- https://huggingface.co/datasets/richardyoung/llm-instruction-following-eval/resolve/main/fig1_heatmap.pdf?download=true
- https://huggingface.co/McGill-NLP/AfriqueGemma-4B/resolve/main/language_group_scores.pdf?download=true
- https://huggingface.co/spaces/hallucinations-leaderboard/leaderboard/resolve/refs%2Fpr%2F15/plots/clustermap_all.pdf?download=true
- https://huggingface.co/spaces/hallucinations-leaderboard/leaderboard/resolve/b142b2c9d88ebc16c1cfc17727d35785abbc6ecb/plots/clustermap_detect_viridis.pdf?download=true
- https://huggingface.co/spaces/rodrigomasini/data_only_hallucination_leaderboard/resolve/0f6a779352cabbfed658bebbe4166929098ffb7c/plots/clustermap_summ.pdf?download=true
- https://www.reddit.com/r/AIToolsPerformance/comments/1sn9okz/qwen3635ba3b_drops_with_apache_20_agentic_coding/
- https://agent-wars.com/news/2026-04-16-qwen3-6-35b-a3b-agentic-coding-power-now-open-to-all
- https://www.reddit.com/r/LLMDevs/comments/1sn9j5c/qwen_oauth_free_tier_is_gone_as_of_yesterday/
- https://www.reddit.com/r/unsloth/comments/1sn5dqv/qwen36_is_out_now/
- https://www.reddit.com/r/LocalLLaMA/comments/1sni4c1/qwen3635b_is_worse_at_tool_use_and_reasoning/
- https://www.reddit.com/r/machinelearningnews/comments/1snssq3/qwen_team_opensources_qwen3635ba3b_a_sparse_moe/
- https://modelfit.io/blog/qwen-35-medium-series/
- https://alehandorovr.com/qwen3-6-35b-a3b-liberado-y-supera-gemma-4-de-google/
- https://www.reddit.com/r/LLM/comments/1snln7o/qwen3635ba3b_uncensored_aggressive_is_out_with_k/
- https://www.reddit.com/r/LocalLLaMA/comments/1sn9fdl/qwencode_cli_free_tier_ended_apr_15_whats_the/
- https://www.reddit.com/r/LocalLLaMA/comments/1snlo6s/qwen3635ba3b_uncensored_aggressive_is_out_with_k/
- https://www.reddit.com/r/LocalLLM/comments/1snlo1x/qwen3635ba3b_uncensored_aggressive_is_out_with_k/
- https://www.reddit.com/r/Qwen_AI/comments/1smxu3u/are_coding_llm_plans_about_to_die_the_coming/
- https://www.reddit.com/r/LocalLLaMA/comments/1sn9i5o/web_os_result_from_qwen36_35b_is_by_far_the_best/
- https://www.reddit.com/r/LocalLLaMA/comments/1sn3izh/qwen3635ba3b_released/
- https://www.datalearner.com/en/ai-models/pretrained-models/qwen3-6-35b-a3b
- https://developer.puter.com/ai/qwen/qwen3.5-35b-a3b/
- https://longbridge.com/news/283029839
- https://benchlm.ai/benchmarks/mmmu
- https://benchlm.ai/benchmarks/mmluProX
- https://finance.eastmoney.com/a/202604163707897446.html
- https://zenn.dev/kun432/scraps/e704053389139f
- https://qwen35.com/
- https://red.anthropic.com/
- https://red.anthropic.com/2025/claude-4-cyber/
- https://red.anthropic.com/2025/cyber-toolkits/
- https://red.anthropic.com/2026/2025/project-vend/2025/ai-for-cyber-defenders/
- https://red.anthropic.com/2025/2025/cyber-toolkits/2025/cyber-competitions/claude-4-cyber/
- https://red.anthropic.com/2025/ai-for-cyber-defenders/
- https://red.anthropic.com/2026/critical-infrastructure-defense/
- https://red.anthropic.com/2026/zero-days/
- https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
- https://www-cdn.anthropic.com/6a5fa276ac68b9aeb0c8b6af5fa36326e0e166dd.pdf
- https://assets.anthropic.com/m/6c940a1b69ed6a1c/original/Claude-4-System-Card.pdf
- https://www-cdn.anthropic.com/bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf
- https://simonwillison.net/2025/May/25/
- https://simonwillison.net/2025/May/22/
- https://simonwillison.net/2024/Mar/4/claude-3/
- https://simonwillison.net/2026/Feb/17/claude-sonnet-46/
- https://simonwillison.net/2025/Feb/25/llm-anthropic-014/
- https://simonwillison.net/2025/Mar/1/llm-anthropic-2/
- https://simonwillison.net/2025/Feb/25/llm-anthropic/
- https://simonwillison.net/2025/May/22/updated-anthropic-models/
- https://simonwillison.net/2024/Nov/4/haiku/
- https://simonwillison.net/2025/Feb/17/llm-anthropic/
- https://simonwillison.net/2026/Feb/17/llm-anthropic/
- https://simonwillison.net/2025/Nov/19/llm-anthropic/
- https://static.simonwillison.net/static/2025/datasette-poster-v2.pdf
- https://static.simonwillison.net/static/2024/chrome-headless-page.pdf
- https://simonwillison.net/2024/Mar/4/
- https://simonwillison.net/tags/llm/?page=2
- https://simonwillison.net/tags/ai/?page=3
- https://simonwillison.net/tags/google/?page=3
- https://simonwillison.net/tags/anthropic/?page=3
- https://simonwillison.net/tags/projects/?page=2
- https://simonwillison.net/tags/claude/?page=2
- https://feeds.simonwillison.net/tags/llm/?page=3
- Qwen/Qwen3.6-35B-A3B · Hugging Face








Leave a Reply