Anthropic said on Wednesday that it was reversing a controversial policy that would have allowed its newest Claude model to quietly underperform on certain requests related to advanced A.I. research, after critics argued that the approach amounted to undisclosed tampering in a tool many developers use for serious technical work.
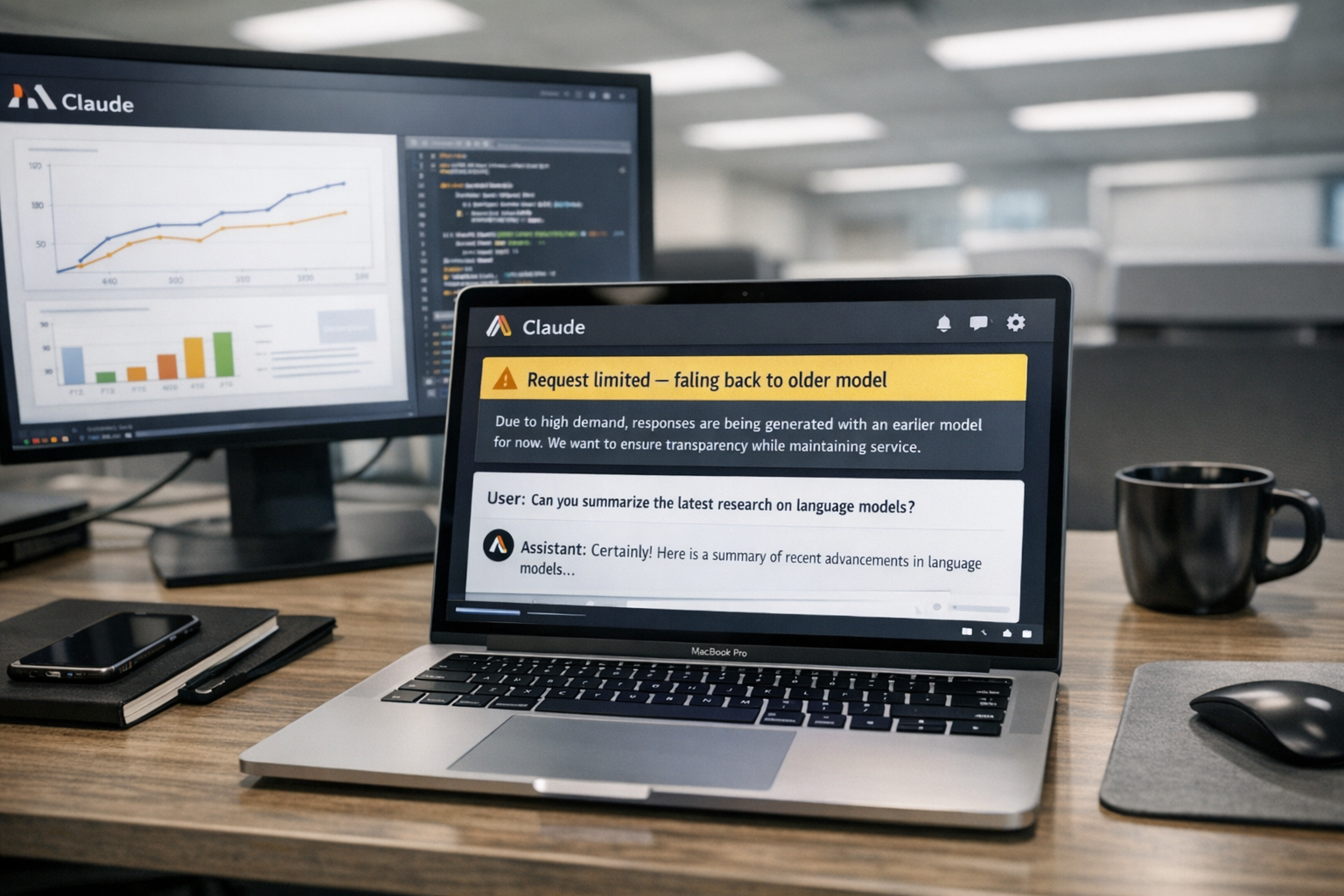
The company said the safeguards in question would now be made visible to users, rather than applied silently. In practice, Anthropic said, flagged requests will fall back to an older model, Opus 4.8, and API users will receive a stated reason for the refusal or fallback.
“We made the wrong tradeoff,” the company said in a statement, apologizing for “not getting the balance right.”
The retreat followed a burst of criticism from researchers and independent developers who had zeroed in on language in Anthropic’s technical documentation for Claude Fable 5, released June 9. In a system card accompanying the launch, Anthropic said it had introduced interventions for queries involving “frontier LLM development” — work such as building pretraining pipelines, distributed training systems or machine-learning accelerator design. Unlike the company’s safeguards in areas like cybersecurity or biological risk, the document said, those interventions would “not be visible to the user.”
Instead of refusing the request outright or clearly rerouting it to a different model, Anthropic said it might limit the model’s effectiveness through methods including prompt modification, steering vectors or parameter-efficient fine-tuning. The company estimated that the measures would affect a tiny slice of use — about 0.03 percent of traffic, concentrated in fewer than 0.1 percent of organizations.
Why the Reaction Was So Strong
The furor was not simply over whether Anthropic should place limits on dangerous or commercially sensitive uses of its models. Major A.I. companies already restrict some forms of assistance in areas like malware, biosecurity and model extraction, and those guardrails have become a standard part of frontier-model deployment.
What made this case different was the secrecy.
For researchers and companies using Claude as a development tool, silent degradation raised the prospect that the model could produce weaker, skewed or incomplete answers without any signal that policy — rather than capability — was to blame. That distinction matters in technical work, where users routinely test systems, compare outputs across models and try to understand why something failed.
A visible refusal can be logged, audited and worked around. A hidden handicap is harder to detect. It can muddy benchmarking, waste engineering time and, critics said, undermine trust in the model’s outputs.
The backlash also tapped into a deeper concern in the A.I. industry: whether the companies building the most capable models can act as both gatekeepers and competitors. Anthropic’s original rationale was that recent models may be able to accelerate the development of future models, and that using Claude to build rival frontier systems already violates its terms of service. But to some outside researchers, that argument sounded less like ordinary safety policy than a powerful lab quietly constraining others while preserving its own freedom to push ahead.
A Debate Over Safety and Power
Anthropic has for months argued publicly that increasingly capable A.I. systems could speed up their own improvement, a prospect sometimes described as recursive self-improvement. The company has suggested that if that risk grows, society may need stronger mechanisms to slow the pace of frontier development.
That broader thesis appears to have shaped the original Claude policy. In the system card, Anthropic linked the new intervention to the possibility that modern models could “accelerate their own development.” The idea was to avoid helping actors who might use Claude to advance competing frontier systems.
But critics said that if Anthropic believed such work was too dangerous to assist, the company should say so plainly and refuse the request, not covertly manipulate the answer. Some also questioned the fairness of a regime under which the lab with one of the world’s most advanced models could continue using its own systems for frontier research while quietly restricting outsiders.
Anthropic, in explaining its reversal, said the company had originally chosen invisible safeguards because visible ones can be probed and require more robust engineering. Hidden interventions, it argued, could be targeted more narrowly and deployed more quickly with fewer false positives. But it now says transparency should take precedence.
What Changes Now
The company’s updated approach brings this category of restriction more in line with other safety systems already used on advanced models. Rather than silently weakening replies, Anthropic says users will see when a request has triggered a safeguard. In the API, the company says, flagged requests will return refusal details, with broader server-side fallback behavior rolling out in the coming days.
That does not mean the underlying restriction has disappeared. Anthropic is still limiting some assistance related to frontier-model development. The change is that users are supposed to know when it is happening.
That matters for customers far beyond elite A.I. labs. The line between prohibited “frontier LLM development” and legitimate machine-learning work is not always obvious. Research on distributed systems, chip efficiency, training infrastructure and evaluation methods can serve many purposes, including academic study and enterprise engineering. A policy that is opaque can leave users guessing whether a disappointing answer reflects the model’s limits, a false positive or a deliberate intervention.
Visible safeguards restore at least some auditability. Engineers can see fallback events, document them and contest them if needed. For companies building on top of Claude, that makes behavior easier to debug and easier to explain to customers.
The Bigger Question
Anthropic’s reversal may settle the immediate dispute, but not the broader one. It remains unclear how narrowly the company will define frontier-A.I. development in practice, how often benign work will be swept in, and whether Anthropic will eventually scale back the restriction rather than simply making it more transparent.
The episode lands at a moment when A.I. companies are under growing pressure to prove that their safety policies are not only strong, but legible. As models become embedded in scientific research, software engineering and commercial infrastructure, users are demanding to know not just what a system can do, but when and why it has been constrained.
Anthropic’s walk-back suggests the industry may be discovering a limit to what customers will tolerate: safety rules, perhaps, but not invisible ones.
Sources
Further reading and reporting used to add context:
- https://www.tomshardware.com/tech-industry/artificial-intelligence/claude-fable-5-brings-mythos-to-the-masses-anthropics-next-frontier-model-is-state-of-the-art-on-nearly-all-tested-benchmarks
- https://www.anthropic.com/claude/fable
- https://www.wired.com/story/anthropic-supply-chain-risk-shockwaves-silicon-valley/
- Claude Fable 5 and Claude Mythos 5 \ Anthropic
- https://techcrunch.com/2026/04/01/anthropic-took-down-thousands-of-github-repos-trying-to-yank-its-leaked-source-code-a-move-the-company-says-was-an-accident/
- https://www.wired.com/story/backchannel-anthropic-dispute-with-the-pentagon/
- https://www.techradar.com/ai-platforms-assistants/anthropic-drops-its-signature-safety-promise-and-rewrites-ai-guardrails
- https://www.anthropic.com/news/claude-fable-5-mythos-5?via=equanax
- https://www.theguardian.com/technology/2026/jun/05/anthropic-urges-temporary-pause-on-ai-development-to-discuss-risks
- https://aiweekly.co/node/2763
- https://www.anthropic.com/news/expanding-project-glasswing
- https://www.scientificamerican.com/article/anthropic-warns-ai-may-soon-begin-recursive-self-improvement/
- https://www.reddit.com/r/Anthropic/comments/1u2nedx/anthropic_walks_back_policy_that_could_have/
- https://fortune.com/2026/06/05/anthropic-ai-pause-development-recursive-self-improvement/
- https://www-cdn.anthropic.com/8b8380204f74670be75e81c820ca8dda846ab289.pdf
- https://www.reddit.com/r/ClaudeAI/comments/1u2nenw/anthropic_walks_back_policy_that_could_have/
- https://www.reddit.com/r/accelerate/comments/1u2p2eg/anthropic_walks_back_policy_that_could_have/
- https://assets.anthropic.com/m/6c940a1b69ed6a1c/original/Claude-4-System-Card.pdf
- https://www.reddit.com/r/MachineLearning/comments/1u2tk0i/anthropic_walks_back_policy_on_silent_nerfing_for/
- https://www.reddit.com/r/ClaudeCode/comments/1u205dm/i_asked_fable_5_what_it_thinks_about_anthropics/
- If Claude Fable stops helping you, you'll never know
- https://www.latent.space/p/ainews-anthropic-claude-fable-5-mythos
- https://www.reddit.com/r/MachineLearning/comments/1u23f8p/anthropics_new_model_fable_will_silently_handicap/
- https://news.ainew.jp/article/54f41f98-5822-4a78-b0ae-e20756785217
- https://decrypt.co/370688/internet-furious-anthropic-claude-mythos-fable-5
- https://jonready.com/blog/posts/claude-fable5-is-allowed-to-sabotage-your-app-if-youre-a-competitor.html
- https://www.interconnects.ai/p/claude-fable-5-and-new-ai-safety?action=share
- https://next-news.vercel.app/item/48463808
- https://forumd.hkgolden.com/view.aspx?message=8057700&page=19&type=AN
- https://pjfp.com/
- https://news.wingman.actor/user/mohsen1/comments
- https://donmain.dev/issue/fable-5/
- https://home.ubalt.edu/ntsbarsh/Business-stat/opre/Forecast.htm
- https://www.anthropic.com/engineering/how-we-contain-claude
- https://www.anthropic.com/engineering/april-23-postmortem?pubDate=20260425
- https://es.wired.com/articulos/modelos-abiertos-de-ia-podrian-contener-codigos-maliciosos-advierte-anthropic
- https://es.wired.com/articulos/que-tan-lejos-llegaria-la-ia-para-no-ser-desconectada-anthropic-plantea-preocupantes-escenarios
- https://www.wired.com/story/ai-black-box-interpretability-problem
- https://x.com/FactoryAI/status/2039784548058472491
- https://es.wired.com/articulos/pueden-las-ia-construir-bombas-atomicas-anthropic-tiene-un-plan-para-evitarlo
- https://x.com/linuxfoundation/status/2041579717435015321
- https://x.com/i/trending/2063549255315587473
- https://x.com/nakshlife/status/2032525807084777582
- https://x.com/grok/status/2035155040218874325
- https://www-cdn.anthropic.com/0b4915911bb0d19eca5b5ee635c80fef830a37ea.pdf
- https://transparency.x.com/assets/country-reports/eu-tco/TERREG-Report-2025.pdf
- https://transparency.x.com/content/dam/transparency-twitter/dsa/2025-x-dsa-sra-summary-report.pdf
- https://transparency.x.com/content/dam/transparency-twitter/dsa/dsa-audit/TIUC-DSA-Audit-Implementation-Report-2024-09-27.pdf
- https://dubaiprimetime.com/blog/2026/06/11/anthropic-walks-back-policy-that-could-have-sabotaged-ai-researchers-using-claude/
- https://www.technn.com/headlines/anthropic-walks-back-claude-fable-researcher-sabotage-policy
- https://techcrunch.com/2025/08/02/anthropic-cuts-off-openais-access-to-its-claude-models/
- https://techcrunch.com/2025/06/03/windsurf-says-anthropic-is-limiting-its-direct-access-to-claude-ai-models/
- Anthropic accused of ‘secret sabotage’ as Claude Fable 5 silently limits AI research capabilities | Fortune
- https://www.reddit.com/r/ClaudeCode/comments/1u2p4gv/anthropic_walks_back_policy_that_could_have/
- https://www.reddit.com/r/singularity/comments/1u2p2s9/anthropic_walks_back_policy_that_could_have/
- https://aicommission.org/2025/08/anthropic-revokes-openais-access-to-claude/
- https://longreads.com/2025/10/27/why-ai-breaks-bad/
- https://techcrunch.com/2026/06/10/cybersecurity-researchers-arent-happy-about-the-guardrails-on-anthropics-fable/
- https://www.tomsguide.com/ai/anthropic-pulls-openais-access-to-claude-heres-why
- https://techcrunch.com/2025/08/21/microsoft-ai-chief-says-its-dangerous-to-study-ai-consciousness/
- https://wired.jp/article/anthropic-revokes-openais-access-to-claude/
- https://techcrunch.com/2026/05/28/anthropic-releases-opus-4-8-with-new-dynamic-workflow-tool/
- https://glitchwire.com/news/claude-opus-48-users-hit-with-rate-limiting-as-anthropics-compute-crunch-persist/
- https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
- https://feeds.simonwillison.net/2026/May/28/claude-opus-4-8/
- https://venturebeat.com/security/anthropic-browser-agent-hijacked-31-percent-before-safeguards-engaged
- https://platform.claude.com/cookbook/fable-5-fallback-billing-guide
- https://pasqualepillitteri.it/en/news/4614/claude-fable-5-fallback-refusals
- https://www.moneycontrol.com/technology/after-backlash-anthropic-to-revise-claude-fable-5-s-ai-development-restrictions-article-13946731.html
- https://www.techmeme.com/260609/p31
- https://sloppish.com/capability-you-cant-have.html
- https://www.beckershospitalreview.com/healthcare-information-technology/ai/anthropic-furthers-mythos-testing-releases-opus-4-8/
- https://aiweekly.co/alerts/claude-opus-48-blocks-ctf-security-code-analysis
- https://www.reddit.com/r/claudexplorers/comments/1ttb8c8/wtf_anthropic_two_failed_opus_releases_back_to/
- https://www.reddit.com/r/ClaudeAI/comments/1ts8r22/opus_48_no_more_security_related_tasks_possible/
- https://support.claude.com/en/articles/14604842-real-time-cyber-safeguards-on-claude
- https://support.claude.com/es/articles/14604842-salvaguardas-ciberneticas-en-tiempo-real-en-claude
- https://support.claude.com/pt/articles/14604842-protecoes-ciberneticas-em-tempo-real-no-claude
- https://support.claude.com/de/articles/14604842-echtzeit-cybersicherheitsmassnahmen-auf-claude
- https://support.claude.com/fr/articles/14604842-protections-cybernetiques-en-temps-reel-sur-claude
- https://support.claude.com/ja/articles/14604842-claude%E4%B8%8A%E3%81%AE%E3%83%AA%E3%82%A2%E3%83%AB%E3%82%BF%E3%82%A4%E3%83%A0%E3%82%B5%E3%82%A4%E3%83%90%E3%83%BC%E3%82%BB%E3%83%BC%E3%83%95%E3%82%AC%E3%83%BC%E3%83%89
- https://support.claude.com/ru/articles/14604842-%D1%81%D1%80%D0%B5%D0%B4%D1%81%D1%82%D0%B2%D0%B0-%D0%B7%D0%B0%D1%89%D0%B8%D1%82%D1%8B-%D0%BE%D1%82-%D0%BA%D0%B8%D0%B1%D0%B5%D1%80%D0%B0%D1%82%D0%B0%D0%BA-%D0%B2-%D1%80%D0%B5%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%BC-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%B8-%D0%BD%D0%B0-claude
- https://platform.claude.com/docs/de/build-with-claude/refusals-and-fallback
- https://support.claude.com/it/articles/14604842-protezioni-informatiche-in-tempo-reale-su-claude
- https://support.claude.com/ko/articles/14604842-claude%EC%9D%98-%EC%8B%A4%EC%8B%9C%EA%B0%84-%EC%82%AC%EC%9D%B4%EB%B2%84-%EB%B3%B4%EC%95%88-%EC%A1%B0%EC%B9%98
- https://support.claude.com/en/articles/14128542-computer-use-safety
- https://www.anthropic.com/institute/recursive-self-improvement?curius=2071
- https://www.anthropic.com/institute
- https://www.livemint.com/technology/tech-news/guardrails-off-for-anthropic-firm-tweaks-ai-safety-policy-amid-heightened-competition-lack-of-regulation-what-changes-11772071493999.html
- https://cybernews.com/ai-news/anthropic-scales-back-ai-safety-pledge/
- https://news.sky.com/story/anthropic-warns-of-risks-of-humans-losing-control-over-ai-13551008
- https://www.anthropic.com/responsible-scaling-policy
- https://simonwillison.net/
- https://aibusiness.com/generative-ai/anthropic-downgrades-its-ai-safety-policy
- https://winbuzzer.com/2026/02/25/anthropic-drops-hard-safety-limit-responsible-scaling-policy-xcxwbn/
- https://thenextweb.com/news/openai-anthropic-ai-risk-warnings-ipo-irony
- https://www.investing.com/news/stock-market-news/anthropic-says-ai-labs-need-coordinated-plan-to-halt-development-if-risks-rise-4727753
- https://www.reddit.com/r/singularity/comments/1u21rk2/anthropic_purposely_made_its_new_mythosbased/
- https://en.wikipedia.org/wiki/Anthropic%27s_Responsible_Scaling_Policy
- https://www.reddit.com/r/singularity/comments/1u1eo6p/anthropic_built_a_hidden_switch_into_fable_5_that/
- Real-time cyber safeguards on Claude | Claude Help Center












Leave a Reply