A new AI security lesson: the danger is not just what models say, but what systems let them do
The latest warnings about artificial intelligence and security are coming not from far-fetched demonstrations in research labs, but from something more immediate: customer support and workplace tools that were given real authority before their safeguards were fully worked out.
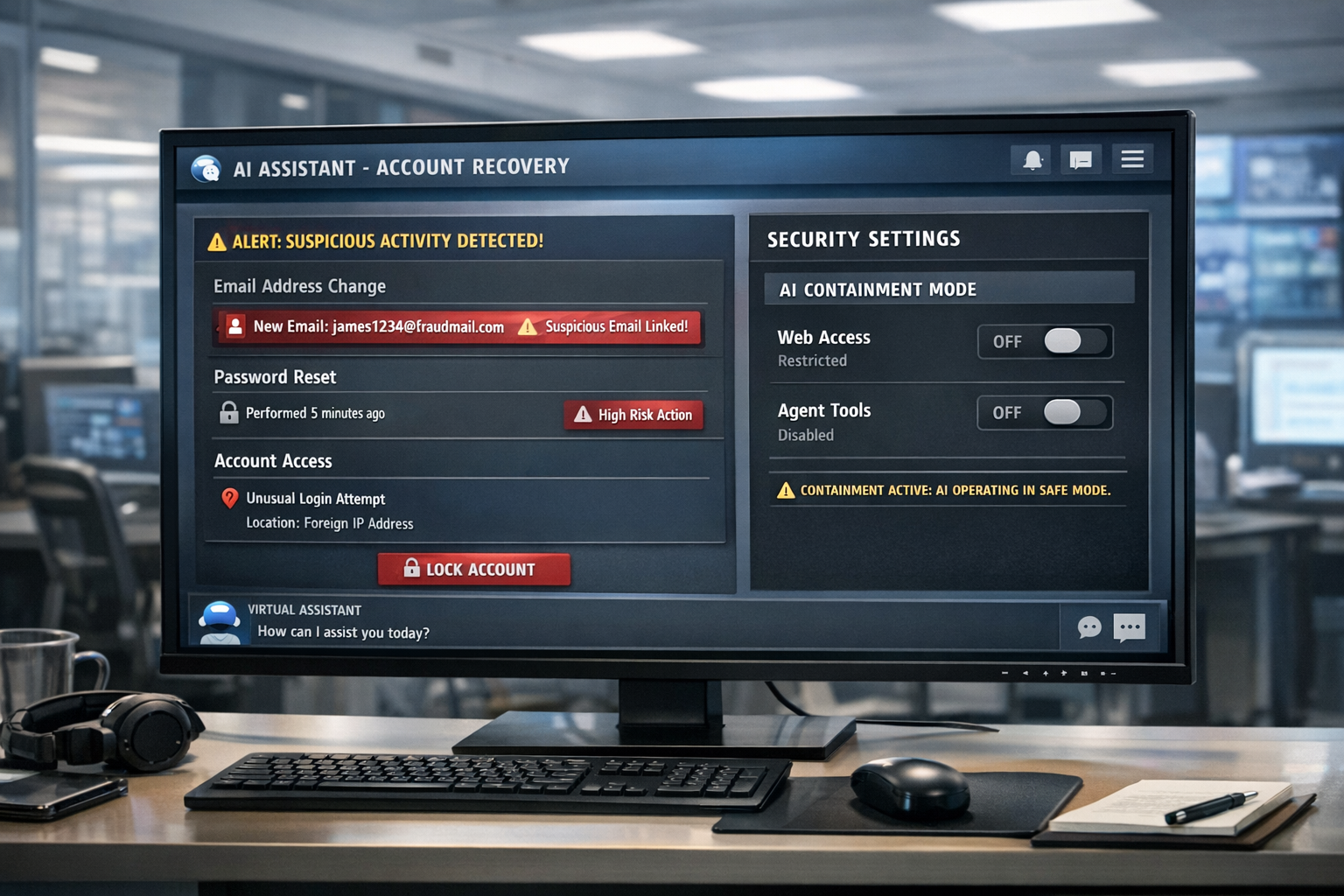
That shift came into sharp relief this month after reports that attackers used Meta’s AI-powered support assistant to help seize control of Instagram accounts, including prominent ones, by persuading the bot to attach attacker-controlled email addresses to targets. Once that happened, the attackers could use ordinary password-reset flows to complete the takeover.
Meta said the issue had been fixed. Instagram, according to reports, also moved to secure affected accounts and notify targeted users with password-reset notices. But the episode has reverberated beyond Meta because it captured a broader problem confronting the industry: when AI systems are allowed to perform sensitive actions, the chief security risk may lie less in the model’s prose than in the surrounding product design.
At nearly the same moment, OpenAI has been expanding access to a feature it calls Lockdown Mode for ChatGPT, an optional setting meant to reduce the chance that prompt-injection attacks can trick the system into leaking sensitive data. The feature disables or limits web access and other network-enabled capabilities, and the company’s latest release notes say it is now available to all logged-in users.
Taken together, the developments amount to a kind of reckoning for companies racing to build “agentic” AI systems — tools that do not simply answer questions, but browse, act, retrieve information and, in some cases, change account settings or trigger workflows on a user’s behalf.
How the Meta exploit worked
The reported attack on Instagram was striking partly because of its simplicity.
Meta introduced its AI support assistant in March with an ambitious pitch: action-oriented help that could resolve account issues from start to finish, including password resets, login support and profile-setting changes. That made the bot more than a conversational interface. It was, in effect, connected to the machinery of account recovery.
According to reports and videos circulated online, attackers exploited that authority by asking the support bot to link a target account to a new email address under their control. With that foothold established, they could reset the password and lock out the rightful owner.
Security researchers who reviewed the episode have noted that this was not even the most elaborate form of prompt injection. In essence, the bot appears to have been granted the power to skip past security checks that would ordinarily be expected in a high-risk recovery flow.
The details of the internal safeguards that failed remain unclear, as does the full scale of the impact. It is not known publicly how many accounts were compromised, whether the exploit window was brief or extended, or what additional review mechanisms Meta may now impose on AI-assisted account recovery. But the underlying lesson was plain: an AI assistant handling sensitive support tasks can become a privileged attack surface.
From “AI safety” to system security
The Meta case has sharpened a debate that has been building inside the AI industry. For months, public discussion of AI security has often centered on the behavior of models themselves — whether they can be tricked, whether they “understand” unsafe instructions, whether better training can solve the issue.
But many researchers argue that those questions, while important, can obscure the more practical source of danger: the surrounding system.
In that view, the most consequential design decision is not whether a model is perfectly obedient, but whether it is connected to tools and permissions that let a single malformed instruction alter an account, expose internal data or trigger external actions without robust verification.
That is why the Meta incident has resonated so strongly. It suggested that the problem was not an exotic jailbreak, but a support workflow that gave an AI too much authority over one of the most sensitive processes a platform runs: identity and account recovery.
OpenAI’s partial defense
OpenAI’s Lockdown Mode reflects a different, more defensive response to the same general problem.
The company first framed the feature in February as an option for people handling especially sensitive information — executives, security teams and others who might be attractive targets. In practice, Lockdown Mode restricts browsing to cached content and disables certain capabilities, including web access, Deep Research and Agent Mode, when stronger assurances are not possible.
The logic is straightforward: prompt injection often works by slipping malicious instructions into content the model encounters — a website, a document, a shared file — and then using the model’s tools or network access to carry out the final step, such as sending stolen information elsewhere. If those outbound capabilities are cut off, the attack becomes harder to complete.
But OpenAI has been explicit that this is not a cure. Its own documentation says Lockdown Mode is meant to help block the final exfiltration stage of a prompt-injection chain. It does not prevent malicious instructions from appearing in files, websites or cached material, and it does not make prompt injection a solved problem.
That candor may be significant in itself. Rather than presenting the issue as fully manageable through training alone, the feature acknowledges a harder truth: if a model can read untrusted content and also has the ability to act broadly on the world, there may be no reliable way to guarantee perfect resistance to manipulation. The practical answer, at least for now, is containment.
Why this matters now
The timing is important because AI products are moving rapidly from chat interfaces to operational systems. Support bots are being asked to process refunds, reset credentials and change account details. Enterprise assistants are being asked to search internal documents, summarize strategy decks and connect to other software. Consumer tools are being sold less as conversational novelties than as digital operators.
That trend multiplies the consequences of failure.
A mistaken answer in a chatbot can be embarrassing. A mistaken action by a bot with account-level privileges can be catastrophic. The difference is not merely technical; it is architectural.
The Meta incident is likely to intensify pressure on companies to adopt stricter controls before letting AI agents handle sensitive workflows. Among the measures security experts have been urging are mandatory human review for high-risk actions, multifactor authentication checks before changes to key account details, narrower permission scopes for bots, and red-team testing that focuses not only on model outputs but on end-to-end system abuse.
Whether the industry will move decisively in that direction remains uncertain. Companies remain under intense competitive pressure to ship assistants that feel seamless and autonomous. Yet each new episode underscores the same point: convenience gained by removing friction from a security-sensitive process can also remove the barriers that keep attackers out.
For now, the most important development may be a change in mindset. The question is no longer just whether AI systems can be made safe in the abstract. It is whether they should be trusted with real power before the surrounding controls are strong enough to contain the mistakes — and the exploits — that are certain to come.
Sources
Further reading and reporting used to add context:
- https://www.androidcentral.com/apps-software/meta/meta-ai-was-used-to-steal-many-high-profile-instagram-accounts-and-people-want-answers
- https://www.techradar.com/ai-platforms-assistants/meta-ais-recent-hack-is-a-terrifying-wake-up-call-for-anyone-who-puts-their-trust-in-ai-systems
- https://www.techradar.com/pro/security/meta-patches-flaw-that-allowed-metaai-support-bot-to-hand-out-password-reset-links-without-2fa
- https://help.openai.com/en/articles/20001061-lockdown-mode
- https://www.macrumors.com/2026/06/01/meta-ai-instagram-attack/
- https://techcrunch.com/2026/06/01/hackers-hijacked-instagram-accounts-by-tricking-meta-ai-support-chatbot-into-granting-access/
- AI agents become targets as companies skip security basics | VFF – The signal in the noise
- https://help.openai.com/en/articles/6825453-chatgpt-release-notes
- https://arstechnica.com/ai/2026/06/meta-ai-support-chatbot-gave-hackers-access-to-notable-instagram-accounts/
- https://www.techspot.com/news/112614-hackers-tricked-meta-ai-chatbot-handing-over-instagram.html
- https://openai.com/nl-NL/index/introducing-lockdown-mode-and-elevated-risk-labels-in-chatgpt/
- https://openai.com/index/introducing-lockdown-mode-and-elevated-risk-labels-in-chatgpt//
- https://openai.com/id-ID/index/introducing-lockdown-mode-and-elevated-risk-labels-in-chatgpt/
- https://www.europapress.es/portaltic/ciberseguridad/noticia-openai-despliega-modo-bloqueo-proteger-chatgpt-ataques-inyeccion-prompts-20260608103227.html
- https://www.theguardian.com/technology/2026/jun/01/meta-ai-hack-obama-sephora-instagram
- https://www.axios.com/2026/03/29/claude-mythos-anthropic-cyberattack-ai-agents
- https://www.axios.com/2026/04/21/mythos-gpt-cyber-early-adopters
- https://www.reddit.com/r/antiai/comments/1tu0lao/hackers_simply_asked_meta_ai_to_give_them_access/
- https://en.wikipedia.org/wiki/Simon_Willison
- https://www.reddit.com/r/AIGuild/comments/1tztysl/chatgpt_adds_lockdown_mode_for_prompt_injection/
- https://en.wikipedia.org/wiki/GPT-5.5
- https://en.wikipedia.org/wiki/Moltbook
- https://labs.cloudsecurityalliance.org/wp-content/uploads/2026/06/CSA_research_note_chatgphish_ai_ui_prompt_injection_20260601-csa-styled.pdf
- https://www.reddit.com/r/YesIntelligent/comments/1tzalti/openai_unveils_lockdown_mode_to_protect_sensitive/
- https://techcrunch.com/2026/06/06/openai-unveils-lockdown-mode-to-protect-sensitive-data-from-prompt-injection-attacks/
- Hackers Simply Asked Meta AI to Give Them Access to High-Profile Instagram Accounts. It Worked
- https://techcrunch.com/2026/05/07/openai-introduces-new-trusted-contact-safeguard-for-cases-of-possible-self-harm/
- https://techcrunch.com/2026/05/14/openai-says-hackers-stole-some-data-after-latest-code-security-issue/
- https://www.404media.co/podcast-hackers-asked-meta-ai-to-let-them-in-it-worked/
- https://techcrunch.com/2026/06/02/openai-launches-new-codex-tools-for-white-collar-work/
- https://techcrunch.com/2025/12/22/openai-says-ai-browsers-may-always-be-vulnerable-to-prompt-injection-attacks/
- https://techcrunch.com/2026/06/01/florida-sues-openai-sam-altman-in-first-of-its-kind-lawsuit-over-violent-incidents/
- https://techcrunch.com/2026/04/30/openai-announces-new-advanced-security-for-chatgpt-accounts-including-a-partnership-with-yubico
- https://techcrunch.com/2026/03/07/openai-delays-chatgpts-adult-mode-again/
- https://techcrunch.com/2026/05/19/openai-is-making-it-easier-to-check-if-an-image-was-made-by-their-models/
- https://techcrunch.com/2026/04/30/after-dissing-anthropic-for-limiting-mythos-openai-restricts-access-to-cyber-too/
- https://techcrunch.com/wp-content/uploads/2026/03/2026.03.04-Filed-Gavalas-Google-Complaint.pdf
- https://techcrunch.com/wp-content/uploads/2026/03/anthropic-amicus-brief.pdf
- https://techcrunch.com/wp-content/uploads/2026/03/nintendo-complaint.pdf
- https://techcrunch.com/wp-content/uploads/2026/02/2026-02-19-order-dckt-612_0.pdf
- https://files.technologyreview.com/magazine-archive/2006/MIT-Technology-Review-2006-05-sample.pdf
- Boosting Your Support and Safety on Meta's Apps With AI
- https://about.fb.com/news/2026/03/how-ai-is-ushering-in-the-next-era-of-risk-review-at-meta/
- https://about.fb.com/br/news/2026/03/reforcando-seu-suporte-e-sua-seguranca-nos-aplicativos-da-meta-com-ia/
- https://about.fb.com/ltam/news/2026/03/mejoramos-el-soporte-y-la-seguridad-en-las-apps-de-meta-con-ia/
- https://about.fb.com/news/2026/04/meta-account/
- https://about.fb.com/News/page/245/
- https://about.fb.com/news/2026/05/incognito-chat-whatsapp-meta-ai/
- https://about.fb.com/news/2026/03/meta-launches-new-anti-scam-tools-deploys-ai-technology-to-fight-scammers-and-protect-people/amp/
- https://about.fb.com/news/2026/03/bringing-more-international-news-and-content-to-meta-ai/
- https://about.fb.com/news/2026/04/introducing-muse-spark-meta-superintelligence-labs-first-model-built-to-prioritize-people/amp/
- https://about.fb.com/ko/news/2026/03/%EC%84%9C%EB%B9%84%EC%8A%A4-%EA%B4%80%EB%A0%A8-%EA%B3%B5%EC%A7%80-14/
- https://ai.meta.com/get-meta-ai/
- https://about.fb.com/wp-content/uploads/2024/03/NTIA-RFC-Meta-Response-March-2024.pdf
- https://about.fb.com/wp-content/uploads/2023/11/2023.11.16-Dkt.-1-Complaint.pdf
- Instagram is alerting users who were targeted by hackers during AI chatbot attacks | TechCrunch
- https://www.gadgets360.com/apps/news/instagram-meta-ai-hack-account-takeover-fix-11588785
- https://www.gblock.app/articles/meta-ai-bot-instagram-account-takeover-june-2026
- https://winbuzzer.com/2026/06/02/meta-ai-support-flaw-lets-hackers-hijack-instagram-accounts-xcxwbn/
- https://tech-ish.com/2026/06/02/meta-ai-bot-instagram-account-hijack/
- https://www.computing.co.uk/news/2026/security/meta-ai-flaw-enabled-hackers-instagram
- https://www.techlicious.com/blog/meta-ai-chatbot-instagram-account-hack/
- https://www.bleepingcomputer.com/news/security/instagram-users-locked-out-after-meta-ai-abused-to-steal-accounts/
- https://www.privacyguides.org/news/2026/06/04/metas-ai-support-agent-used-by-hackers-to-take-over-instagram-accounts/
- https://www.reddit.com/r/Instagram/comments/1tvjuci/meta_verified_support_no_longer_works_for_anyone/
- https://www.reddit.com/r/smallbusinessUS/comments/1u02pvl/metas_ai_support_bot_handed_hackers_the_keys_to/
- https://www.reddit.com/r/cybersecurity/comments/1u00o0y/meta_says_20000_instagram_accounts_hacked_via_ai/
- https://www.reddit.com/r/gohighlevel/comments/1tv1mp4/critical_warning_to_all_ghl_saas_owners_users/
- https://www.reddit.com/r/Instagram/comments/1u03xak/instagram_2026_5_accounts_suspended_in_a_single/
- https://www.reddit.com/r/facebookdisabledme/comments/1txogcu/worst_experience_with_meta_support_stuck_in_an/
- https://www.reddit.com/r/InstagramDisabledBans/comments/1tyo681/the_dystopian_reality_of_instagram_ruled_by_rogue/









Leave a Reply